压缩算法在数据集预测中的应用
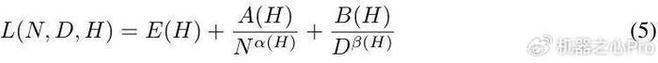
在数据科学和机器学习领域,不同数据集具有不同的特征和结构,而压缩算法能够在一定程度上帮助我们预测数据集的特征。接下来我们将讨论压缩算法在数据集预测中的应用,并探讨其实际应用及指导建议。
数据集的多样性
数据集的多样性体现在以下几个方面:
1.
数据类型多样性
:数据集可能包括数值型、文本型、图像型、时间序列型等不同类型的数据。
2.
数据维度多样性
:数据集的维度可能是一维、二维、多维甚至高维的。
3.
数据分布多样性
:数据集中数据分布可能是正态分布、偏态分布、均匀分布等多种形式。
压缩算法的预测应用
压缩算法在数据集预测中可以发挥以下作用:
1.
特征提取与降维
:压缩算法能够通过提取数据集的主要特征,降低数据维度,减少冗余信息,从而提高预测模型的效率和准确性。
2.
数据重构与恢复
:在预测数据集时,压缩算法可以通过数据重构和恢复,提供更为有效的数据表示,从而改善模型的泛化能力。
3.
异常检测与数据清洗
:压缩算法可以帮助发现数据集中的异常点和噪声,从而进行数据清洗,提高预测模型的鲁棒性。
4.
数据传输与存储优化
:对于大规模数据集,压缩算法可以在数据传输和存储过程中起到优化作用,提高数据处理的效率。
指导建议
在利用压缩算法进行数据集预测时,有以下指导建议:
1.
选择合适的压缩算法
:根据数据集的特点选择合适的压缩算法,例如对于文本型数据可以选择基于词频的压缩方法,对于图像型数据可以选择基于哈夫曼编码的压缩方法等。
2.
注意信息损失
:在使用压缩算法进行数据预测时,需要注意压缩过程中可能带来的信息损失问题,需要在准确性和效率之间进行权衡。
3.
结合特征工程
:在压缩算法的基础上,结合特征工程方法,进一步提取有意义的特征,优化预测模型的性能。
4.
数据可视化与解释
:在压缩算法预测结果的基础上,通过数据可视化和解释,深入理解数据集的特征和结构,为后续决策提供有力支持。
结论
压缩算法在数据集预测中具有重要作用,能够帮助我们更好地理解数据集的特征,提高预测模型的效率和准确性。在实际应用中,我们需要根据数据集的特点选择合适的压缩算法,并结合特征工程等方法进行综合应用,以实现更加可靠的数据预测结果。











