CUDA(Compute Unified Device Architecture)是NVIDIA推出的并行计算平台和编程模型,用于利用GPU进行通用目的计算。深入理解CUDA编程核心对于有效利用GPU的并行计算能力至关重要。以下是一些关键概念和指导,可帮助您开始CUDA编程的学习和应用。
CUDA基于SIMT(Single Instruction, Multiple Threads)模型,将大量的线程组织成线程块(Thread Blocks),线程块又组织成网格(Grids)。这种模型允许GPU同时执行大量线程,以实现高效的并行计算。
理解CUDA内存层次结构对于优化内存访问至关重要。主要的内存类型包括:
全局内存(Global Memory):所有线程可访问,但访问速度较慢。
共享内存(Shared Memory):线程块内共享,访问速度快,但容量有限。
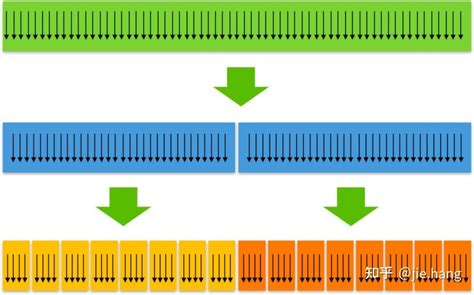
寄存器(Registers):每个线程私有,访问速度最快,但数量有限。
优化内存访问模式,减少全局内存访问,利用共享内存等技术可以提高性能。
核函数是在GPU上执行的并行计算任务。在CUDA中,使用`__global__`修饰符声明的函数即为核函数。核函数由大量线程并行执行,每个线程执行相同的指令,但可以根据线程ID执行不同的操作。
进行CUDA编程的一般步骤包括:
1.
2.
3.
4.
NVIDIA提供了一系列工具用于CUDA开发和调试,包括`nvcc`编译器、CUDAGDB调试器、Visual Profiler等。熟练使用这些工具可以帮助定位和解决CUDA程序中的问题,提高开发效率和性能。
深入理解CUDA编程核心对于充分发挥GPU并行计算能力至关重要。通过掌握并行计算模型、内存层次结构、核函数编写技巧以及并行优化技巧,可以编写高效的CUDA程序。熟悉CUDA工具和调试技术也是提高开发效率和性能的关键。
版权声明:本文为 “联成科技技术有限公司” 原创文章,转载请附上原文出处链接及本声明;











